
Әліпбиіміздің латын қарпіне көшуіне байланысты әлеуметтік желі мен БАҚ-та пікірталас, ақпарат кеңістігінде толқу туғызып жатқан мәселенің ең бастысы әліпбидегі әріп құрамға қатысты болып отыр. Көптеген әліпби нұсқасы көрсетіліп, түрлі топ өз идеясын ұсынып жатыр.
Осы әліпби жобаларын қарастырғанда оларға тән бір ортақ ерекшелік байқалды. Бұл құбылысқа үйреніп кеткеніміз соншалық тіпті мән бермейміз. Әлеуметтік желі, сайт, түрлі платформаларда ұсынған жобаларда латын әліпбиі таңбалары сол қалпы көрініс береді. Ғаламтор таңбаларды бірден таниды, түрін бұзбай коммуникация құралдарының мониторына шығарады. Қалайша сайттар әлемнің әртүрлі жазуындағы алуан әріп таңбаларын таниды? Әріптер әртүрлі әлеуметтік желілер мен мессенджерлерде бірдей жинақы көрінеді, диакритикалық белгілерге де қарамай еш қиындықсыз форматталады. Диакритикалық белгі түгіл қытай иероглифтерін, армян, грузин, еврей, ежелгі грек, копт сияқты көнеден келе жатқан жазу таңбаларын да бірден ажыратады. Осы сұрақтардың жауабын табу мақсатында ізденісімізді сайттардың кодын ақтарудан бастадық.
Ғаламтор парақтарында символдарды тану үшін "charset" (‘character set’ - таңбалар жиынтығы) атрибуты жауап береді. Көп жағдайда "charset" атрибутының жанында UTF-8 (UTF-16, UTF-32) таңбалар кодтауын пайдаланады. UTF-8 (Unicode Transformation Format) - таңбаларды кодтаудың ресми бекітілген және өзіне 1 112 064 таңбаға дейін сыйдыра алатын формат. UTF-8 негізі ISO/IEC 10646 Әмбебап Кодталған Таңбалар Жиынтығы Халықаралық стандартынан алынады. Стандарт ақпараттық технологиялар саласында қолданылады. ISO/IEC 10646 стандарты өз кезегінде Unicode консорциумының кестелеріне сүйенеді.
Unicode жайында біраз ақпарат бере кеткен жөн болмақ. Unicode - 1991 жылы технологиялық компаниялар арасында таңбалардың кодталуын стандарттау бойынша жұмыс тобы негізінде құрылған коммерциялық емес консорциум. Консорциум 1991 жылдан бастап унификацияланған және кодталған таңбалардың кестесі мен әлем тілдерінің жазу жүйелері таңбаларын жариялап келеді. Сондай-ақ Unicode (көне түркі, мысыр, авеста, руна жазуы, сына жазу секілді) қолданыстан шыққан жазуларды, (ескі сирия, манихей, ронго ронго, финикия және т.б.) өлі тілдердің таңбаларын, брайль іздері, валюта таңбаларын, техникалық символдарды, (маджонг, ойын картасы, домино және т.б.) ойын таңбаларын, емоджилерді кодтаумен айналысады. Осы уақытқа дейін Unicode кестелерінің 21 басылымы жарияланды (кестені қараңыз).
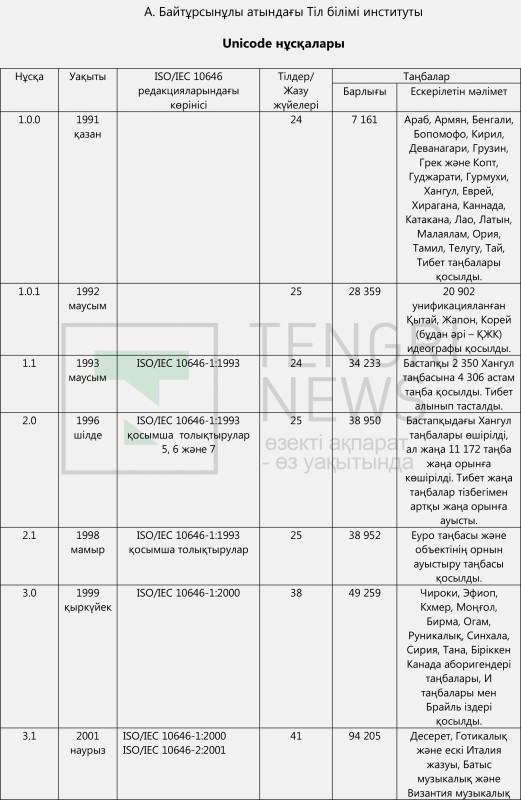
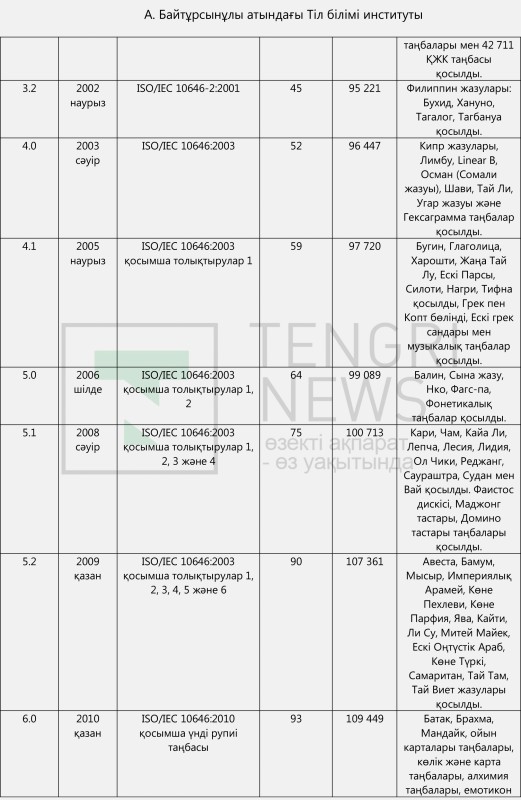
2017 жылы маусымда жарияланған Unicode 10.0 нұсқасында барлығы 136 755 таңба бар. Оның ішінде 954 латын таңбасы бар. 128 US-ASCII және 826 кеңейтілген латын таңбасы. Сондай-ақ 288 фонетикалық таңба бар. Unicode базасындағы таңбалардың алуан түрлілігі мен кеңдігі туралы мұндай ақпараттан хабардар болған кез келген адам үшін 2017 жылдың 11-қыркүйегінде ҚР Парламентінде қазақ тілінің жаңа латын әліпбиін ұсынған Ш.Шаяхметов атындағы Тілдерді үйлестіру орталығының директоры Е. Тілешовтің "смарфтондар мен өзге де жазба құралдары бізге түрлі елден келеді, онда латынның 26 ғана әрпі бар" дегені не әдейі ақпаратты бұрмалау, не білместіктен туындаған қате пікір болып табылады. Себебі қазіргі ақпараттық технологиялар саласындағы стандарттардың икемділігі мен ақпаратты өңдеу, жаңартудың алуан түрлі мүмкіндіктері зор, бұларды жоғарыда келтірілген мәліметтер, тіпті осы мақаланы оқып отырған сайттың коды да дәлелдеп отыр. Мұның бәрі Е.Тілешов мырзаның өз жобасының артықшылығы ретінде келтірген пікірін жоққа шығарады.
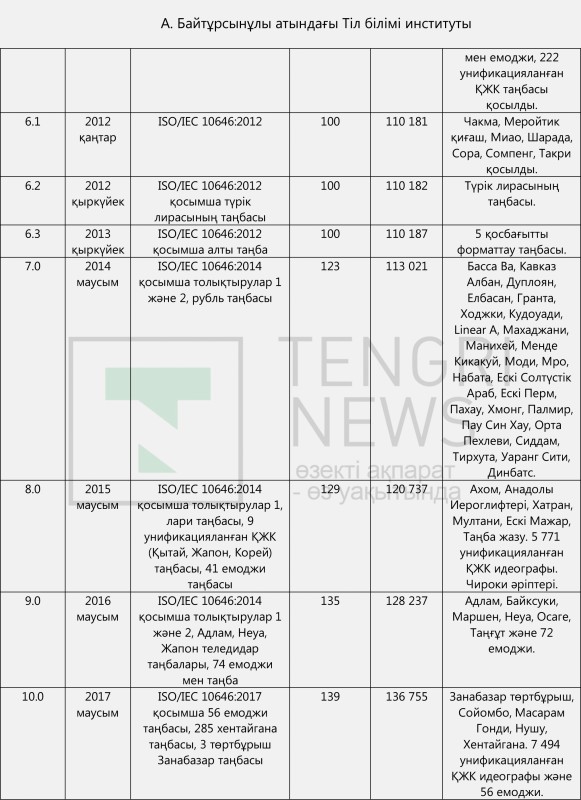
Қазақ тілінің латын әліпбиі жобаларымен танысудан туындаған бақылауларымызға жауап іздеу бізді IT-кеңістіктегі латынграфикалы таңбаларға қатысты техникалық құжаттарды, әртүрлі халықаралық стандарттарды жан-жақты зертеуге итермеледі. Әр құжатпен танысып отырып, күнделікті смартфон бетінде көретін түзу де әдемі әріптердің артында үлкен техникалық негіз (background) бар екеніне көзіміз жетті. Unicode консорциумы 1991 жылдан бері бүкіл таңбаларды стандарттап дайындап, өте жемісті жұмыс жасағанын көрдік. Демек Unicode базасында жоқ деп, пернетақтадағы 26 қаріппен шектеліп, төл дыбыс және төл жазуымыздың принциптерінен бас тартып, әліпбиіміздің тілдік тұрпатынан айырылып қалуға еш негізі жоқ. Сондықтан өзі стандартталып, өзі кодталып қойған Unicode базасындағы латын таңбаларынан тіліміздің ішкі талаптарына жауап беретін әліпби жасамасақ, бізге сын. Unicode кестелеріндегі бас әріп және кіші әріптің 954 латын таңбасы ішінен төл дыбыстарымызды қамтитын, тілдің ішкі заңдылығына сәйкес келетін ыңғайлы әрі ұтымды әліпбиге таңба табылар деген үміт зор.
Мақалада келтірілген барлық дерек ашық ақпарат көздерінен алынды.
Пайдаланылған әдебиеттер тізімі:
https://www.unicode.org/reports/index.html#standards Unicode консорциуымының техникалық құжаттары;
https://www.unicode.org/charts/ Unicode кестелері;
https://www.iso.org/standard/56921.html Әмбебап Кодталған Таңбалар Жиынтығы;
https://www.loc.gov/standards/iso639-2/php/English_list.php ISO 639-2 Тіл Аттарын Көрсету Кодтары.
Автор: Дүйсенов Қуатбек
А.Байтұрсынұлы атындағы
Тіл білімі институтының кіші ғылыми қызметкері,
филология магистрі